Every now and then, your website might get a visit from bots and crawlers, which are not real people. Some bots, such as Googlebot or Bingbot, come by to scan your site’s content for search results. Facebook’s bots drop by to fetch your page title, description and a preview when someone shares your website link on Facebook. There are also other bots that come around to check out your site’s technical setup.
By default, we already filter out traffic from the most common bots and crawlers, but you might come across some that are still being tracked. If that happens, you can intentionally exclude these bots and crawlers.
For a site or app
Available from version 16.0.0. For versions below 16.0.0, go to Menu > Administration > Websites & apps > Settings > Exclude browsers.
To exclude traffic from bots and crawlers, follow these steps:
1. Go to Menu > Administration.
2. Navigate to Sites & apps.
3. On the left, select the site or app you want to work with.
4. Navigate to Data collection > Filters.
5. In Add crawlers, type a user agent name or the full user agent string to define the crawlers.
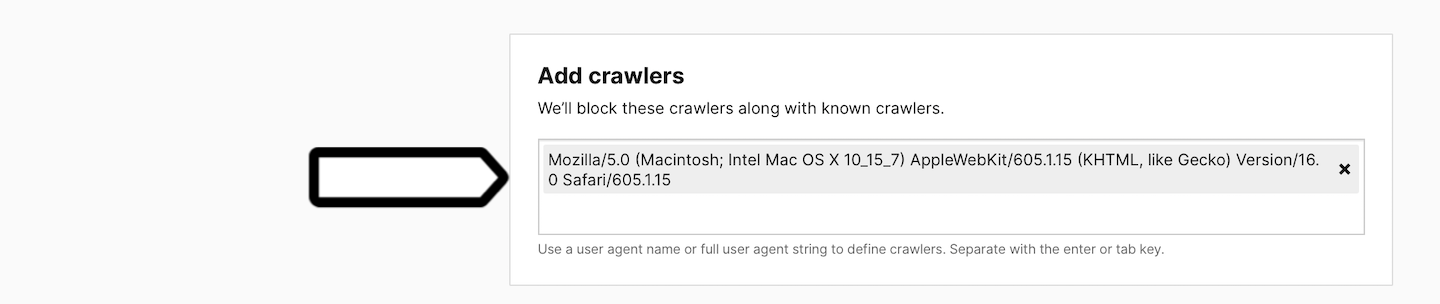
Note: The definition of a crawler supports partial strings. This means that if you enter ‘elephant’, the tracker will block crawlers with a user agent string like ‘elephantine’, ‘elephants’ or ‘big elephants’. However, it doesn’t support wildcards or regular expressions.
6. Done!
For the entire account
Available from version 16.0.0. For versions below 16.0.0, go to Menu > Administration > Platform > Global website settings > Exclude browsers.
To exclude traffic from bots and crawlers, follow these steps:
1. Go to Menu > Administration.
2. Navigate to Account.
3. On the left, click Global site & app settings.
4. Navigate to Data collection > Filters.
5. In Add crawlers, type a user agent name or the full user agent string to define the crawlers.
Note: The definition of a crawler supports partial strings. This means that if you enter ‘elephant’, the tracker will block crawlers with a user agent string like ‘elephantine’, ‘elephants’ or ‘big elephants’. However, it doesn’t support wildcards or regular expressions.
6. Done!
How to define crawlers
If you spot an unusually heavy traffic surge on your site originating from a single source, it might just be a crawler.
To identify the user agent for this crawler, follow these steps:
1. Go to Menu > Analytics.
2. Navigate to Settings.
3. On the left, click Tracker debugger.
4. Look at the session that you believe is a crawler’s session.
5. Click </> to see a raw request.
6. Look for user agent details.
Example:
[
"user-agent",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.0 Safari/605.1.15",
]7. Voila!